Tutorial 42: Slab: Data Processing on the GPU
We saw in the previous tutorial how custom shaders can be executed on the Graphics Processing Unit (GPU) to apply additional shading models to 3D objects. While the vertex processor and fragment processor are inherently designed to render 3D geometry, with a little creativity we can get these powerful execution units to operate on arbitrary matrix data sets to do things like image processing and other tasks. You might ask, "If we can already process arbitrary matrix data sets on the CPU with Jitter Matrix Operators (MOPs), why would we do something silly like use the graphics card to do this job?" The answer is speed.
Recent Trends in Performance
The performance in CPUs over the past half century has more or less followed Moore’s Law, which predicts the doubling of CPU performance every 18 months. However, because the GPU’s architecture does not need to be as flexible as the CPU and is inherently parallelizable (i.e. multiple pixels can be calculated independently of one another), GPUs have been streamlined to the point where performance is advancing at a much faster rate, doubling as often as every 6 months. This trend has been referred to as Moore’s Law Cubed. At the time of writing, high-end consumer graphics cards have up to 128 vertex pipelines and 176 fragment pipelines which can each operate in parallel, enabling dozens of image processing effects at HD resolution with full frame rate. Given recent history, it would seem that GPUs will continue to increase in performance at faster rates than the CPU.
Getting Started
The patches don’t do anything particularly exciting; they are simply a cascaded set of additions and multiplies operating on a matrix of noise (random values of type ). One patch performs these calculations on the CPU, the other on the GPU. In both examples the noise is being generated on the CPU (this doesn’t come without cost). The visible results of these two patches should be similar; however, as you probably will notice if you have a recent graphics card, the performance is much faster when running on the graphics card (GPU). Note that we are just performing some simple math operations on a dataset, and this same technique could be used to process arbitrary matrix datasets on the graphics card.

What about the shading models?
Unlike the last tutorial, we are not rendering anything that appears to be 3D geometry based on lighting or material properties. As a result, this doesn’t really seem to be the same thing as the shaders we’ve already covered, does it? Actually, we are still using the same vertex processor and fragment processor, but with extremely simple geometry where the pixels of the texture coordinates applied to our geometry maps to the pixel coordinates of our output buffer. Instead of lighting and material calculations, we can perform arbitrary calculations per pixel in the fragment processor. This way we can use shader programs in a similar fashion to Jitter objects which process matrices on the CPU (Jitter MOPs).
Provided that our hardware can keep up, we are now mixing two DV sources in real time on the GPU. You will notice that the jit.movie objects and the topmost jit.gl.slab object each have their attribute set to . As covered in the Tutorial 49: Colorspaces, this instructs the jit.movie objects to render the DV footage to chroma-reduced YUV 4:2:2 data, and the jit.gl.slab object to interpret incoming matrices as such. We are able to achieve more efficient decompression of the DV footage using data because DV is natively a chroma-reduced YUV format. Since data takes up one half the memory of ARGB data, we can achieve more efficient memory transfer to the graphics card.
Let’s add some further processing to this chain.

How Does It Work?
The jit.gl.slab object manages this magic, but how does it work? The jit.gl.slab object receives either or messages as input, uses them as input textures to render this simple geometry with a shader applied, capturing the results in another texture which it sends down stream via the message. The message works similarly to the message, but rather than representing a matrix residing in main system memory, it represents a texture image residing in memory on the graphics hardware.
The final display of our composited video is accomplished using a jit.gl.videoplane object that can accept either a or message, using the received input as a texture for planar geometry. This could optionally be connected to some other object like jit.gl.gridshape for texturing onto a sphere, for example.
Moving from VRAM to RAM
The instances of jit.gl.texture that are being passed between jit.gl.slab objects by name refer to resources that exist on the graphics card. This is fine for when the final application of the texture is onto to 3D geometry such as jit.gl.videoplane or jit.gl.gridshape, but what if we want to make use of this image in some CPU based processing chain, or save it to disk as an image or movie file? We need some way to transfer this back to system memory. The jit.matrix object accepts the message and can perform what is called texture readback, which transfers texture data from the graphics card (VRAM) to main system memory (RAM).
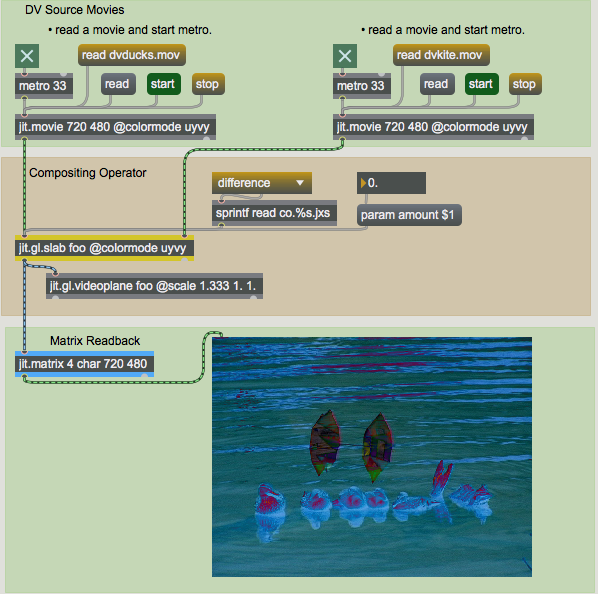
Here we see that the image is being processed on the GPU with jit.gl.slab object and then copied back to RAM by sending the message to the jit.matrix object. This process is typically not as fast as sending data to the graphics card, and does not support reading back in a chroma-reduced UYVY format. However, if the GPU is performing a fair amount of processing, even with the transfer from the CPU to the GPU and back, this technique can be faster than performing the equivalent processing operation on the CPU. It is worth noting that readback performance is being improved in recent generation GPUs.
Summary
In this tutorial we discussed how to make use of jit.gl.slab object to use the GPU for general-purpose data processing. While the focus was on processing images, the same techniques could be applied to arbitrary matrix datasets. Performance tips by using chroma reduced data were also covered, as was how to read back an image from the GPU to the CPU.
See Also
| Name | Description |
|---|---|
| Working with Video in Jitter | Working with Video in Jitter |
| Working with OpenGL | Working with OpenGL |
| Video and Graphics Tutorial 9: Building live video effects | Video and Graphics 9: Building live video effects |
| GL Texture Output | GL Texture Output |
| GL Contexts | GL Contexts |
| jit.fpsgui | FPS meter |
| jit.gl.slab | Process texture data |
| jit.gl.texture | Create OpenGL textures |
| jit.gl.videoplane | Display video in OpenGL |
| jit.matrix | The Jitter Matrix! |
| jit.movie | Play a movie |
| qmetro | Queue-based metronome |